We are nothing without you
CHECKPOINT

Cơ chế lưu dữ liệu trên PostgreSQL
PostgreSQL cũng như một số RDBMS khác. Khi bạn chạy một câu lệnh cập nhật dữ liệu (UPDATE/INSERT/DELETE), dữ liệu vật lý trên đĩa cứng chưa thay đổi mà chỉ thay đổi trên bộ đệm (bộ nhớ dùng chung: PostgreSQL = shared_buffers). Khi bạn tham chiếu dữ liệu (SELECT), trước hết PostgreSQL xem dữ liệu tồn tại trên bộ đệm không, nếu tồn tại dữ liệu sẽ trả về người dùng. Nếu dữ liệu không tồn tại trên bộ đệm, PostgreSQL sẽ truy cập xuống vùng vật lý (ổ đĩa cứng) để lấy dữ liệu, sau đó trước khi trả về cho người dùng dữ liệu đó sẽ được đưa lên bộ đệm.
Cơ chế nêu trên làm tăng tốc độ xử lý nhờ vào việc giảm thiểu I/O trên đĩa cứng.
Độ lớn bộ đệm?
Độ lớn vùng nhớ đệm của PostgreSQL được chỉ định qua parameter shared_buffers (giá trị mặc định của parameter này tuỳ thuộc vào phiên bản PostgreSQL và bộ nhớ hệ thống).
Xem qua ở trên bạn chắc sẽ băn khoăn nếu dữ liệu vừa cập nhật trên bộ đệm, nếu máy tính bị tắt nguồn hoặc OS panic, thì dữ liệu này sẽ bị mất? Bạn yên tâm vì PostgreSQL cũng như các RDBMS khác PostgreSQL có cơ chế roll forward (phục hồi dữ liệu từ transaction log: WAL). Bạn có thể xem qua hình vẽ bên dưới để hiểu thêm.
CHECKPOINT
Khi buffer bị đầy PostgreSQL sẽ ghi những dirty buffers xuống đĩa để chỗ trống cho dữ liệu mới, quá trình này diễn ra liên tục làm tăng cách thao tác thừa sẽ ảnh hưởng tới người dùng. Vì vậy PostgreSQL cần có chức năng CHECKPOINT. CHECKPOINT là cơ chế đồng bộ dữ liệu cập nhật (đã commit) từ bộ nhớ đệm xuống dưới đĩa cứng.
Bạn có thể hình dung đơn giản chức năng CHECKPOINT thực hiện thông qua cơ chế ghi dữ liệu của PostgreSQL như bên dưới.
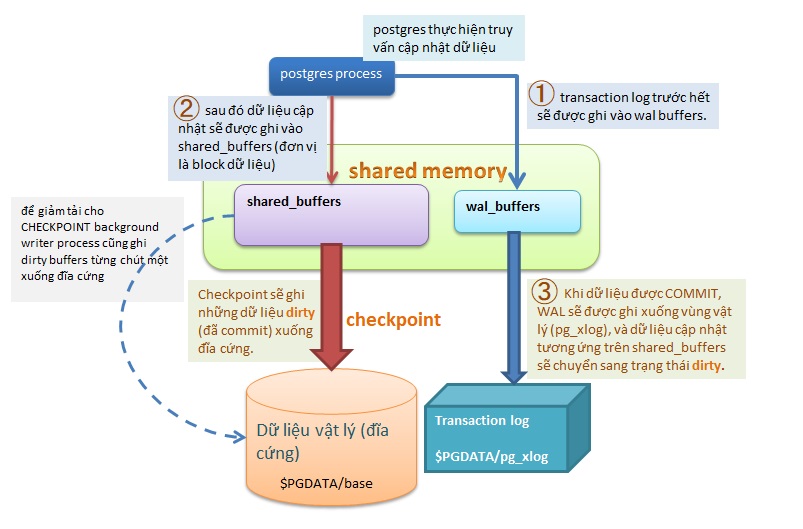
PostgreSQL thực hiện tự động xử lý checkpoint thông qua process checkpointer (phiên bản trước 9.2 thông qua background process).
[postgres@ip-172-31-31-242 ~]$ pg_ctl status
pg_ctl: server is running (PID: 17397)
/usr/pgsql-9.6/bin/postgres
[postgres@ip-172-31-31-242 ~]$ ps -ef | grep 17397
postgres 14946 14348 0 13:11 pts/2 00:00:00 grep --color=auto 17397
postgres 17397 1 0 Apr11 pts/3 00:04:48 /usr/pgsql-9.6/bin/postgres
postgres 17398 17397 0 Apr11 ? 00:00:08 postgres: logger process
postgres 17400 17397 0 Apr11 ? 00:00:10 **postgres: checkpointer process**
postgres 17401 17397 0 Apr11 ? 00:01:08 postgres: writer process
postgres 17402 17397 0 Apr11 ? 00:01:12 postgres: wal writer process
postgres 17403 17397 0 Apr11 ? 00:04:31 postgres: autovacuum launcher process
postgres 17404 17397 0 Apr11 ? 00:08:14 postgres: stats collector process
[postgres@ip-172-31-31-242 ~]$
CHECKPOINT diễn ra khi nào
Thông thường trong vận hành CHECKPOINT xảy ra khi có các điều kiện sau.
-
Khi thời gian từ lần CHECKPOINT trước vượt quá tham số checkpoint_timeout Mặc định parameter này là 5 phút. Như vậy chắc chắn trong vòng 5 phút sẽ có 1 CHECKPOINT xảy ra. Lưu ý: CHECKPOINT xử lý theo cơ chế này, để giảm thiểu disk I/O PostgreSQL làm thao tác này chậm hơn các cơ chế CHECKPOINT khác (sự trì hoãn này phụ thuộc vào giá trị của parameter checkpoint_completion_target).
Khi CHECKPOINT theo cơ chế này xảy ra, PostgreSQL log sẽ có messages như bên dưới(lưu ý set log_checkpoints = on để xuất log khi có CHECKPOINT xảy ra)
[2017-07-08 12:57:05.993 EDT ] LOG: checkpoint starting: time [2017-07-08 12:57:12.020 EDT ] LOG: checkpoint complete: wrote 64 buffers (0.4%); 0 transaction log file(s) added, 0 removed, 0 recycled; write=6.017 s, sync=0.002 s, total=6.026 s; sync files=17, longest=0.001 s, average=0.000 s; distance=730 kB, estimate=970 kB -
Khi lượng dữ liệu transaction log (WAL) lớn hơn max_wal_size (phiên bản trước 9.5 là tham số checkpoint_segments) Khi dung lượng của WAL (transaction log, được lưu trữ trong <thư mục database>/pg_xlog (PostgreSQL 10 -> pg_wal)) vượt quá max_wal_size, CHECKPOINT sẽ tự động diễn ra.
lưu ý: tương quan giữa max_wal_size và checkpoint_segments bạn có thể hiểu là (max_wal_size = checkpoint_segments*3 + 1)
CHECKPOINT theo cơ chế này xảy ra sẽ có messages như bên dưới trong PostgreSQL's log.
[2017-07-08 13:02:42.620 EDT ] LOG: checkpoint starting: xlog [2017-07-08 13:02:43.921 EDT ] LOG: checkpoint complete: wrote 2312 buffers (14.1%); 0 transaction log file(s) added, 1 removed, 1 recycled; write=1.011 s, sync=0.139 s, total=1.311 s; sync files=2, longest=0.139 s, average=0.069 s; distance=32759 kB, estimate=34561 kB -
Ngoài ra CHECKPOINT còn xảy ra trong các trường hợp sau
- Chạy câu lệnh CHECKPOINT từ người dùng (quyền super user)
- Khi Shutdown server PostgreSQL
- Khi khởi động PostgreSQL trong chế độ recovery (roll forward)
- Khi tạo dữ liệu backup từ câu lệnh pg_basebackup
Tinh chỉnh CHECKPOINT sao cho hợp lý để hệ thống chạy tốt cũng là một việc quan trọng. Nếu tăng thời gian tự động CHECKPOINT, thì dữ liệu WAL sẽ nhiều, crash recovery, và CHECKPOINT sẽ mất nhiều thời gian ảnh hưởng tới người dùng. Nếu giảm thời gian này đi thì số lượng CHECKPOINT sẽ tăng lên, làm disk I/O tăng ảnh hưởng tới người dùng. Lưu ý là sau mỗi lần CHECKPOINT, lần cập nhật dữ liệu đầu tiên sẽ lưu cả block dữ liệu (full-page writes) lên WAL điều này làm ảnh hưởng tới disk I/O đáng kể. Vì vậy bạn nên thao khảo sát work-load của người dùng để quyết định tinh chỉnh như thế nào cho PostgreSQL chạy hiệu quả nhé.
Xin vui lòng đặt câu hỏi hoặc thảo luận bằng comments box bên dưới.
© 2017-2018 PostgreSQL Vietnam. All Rights Reserved
Facebook Comments Box