Chào các bạn. Nhân tiện có bạn hỏi về REINDEX nên mình viết bài này để giải thích thêm về REINDEX và VACUUM FULL, khi nào phải thực hiện các thao tác này và cần chú ý những gì khi sử dụng chức năng này. Trong bài viết về VACUUM, mình có giải thích về chức năng và các xử lý mà VACUUM thực hiện. But chưa nói về 2 chức năng liên quan này. Trước khi bắt đầu giải thích về VACUUM FULL và REINDEX, mình xin trả lời trước một số nghi vấn mà lúc tiếp xúc với PostgreSQL các bạn hay gặp phải.
VACUUM có lấy lại dữ liệu phân mảnh cho INDEX không?
Câu trả lời là có. VACUUM lấy lại dữ liệu phân mảnh cho table và những index tương ứng của table đó. But không giống với table, index không có Visibility Map(VM) nên VACUUM thực hiện scan toàn bộ file index tốn nhiều disk I/O để tìm kiếm và thực hiện lấy lại dữ liệu dư thừa. Đây cũng là một điểm bất lợi về performance của VACUUM.
Tại sao cần REINDEX hay VACUUM FULL?
Lý do chính trong vận hành khi thực hiện 2 chức năng này là để khắc phục tình trạng file dữ liệu (table hay index) bị tăng quá lớn.
Hai chức năng này khi chạy sẽ ảnh hưởng nhiều tới hệ thống. Bạn nên tham khảo kỹ chú ý ở cuối bài viết này rồi thực hiện cho đúng.
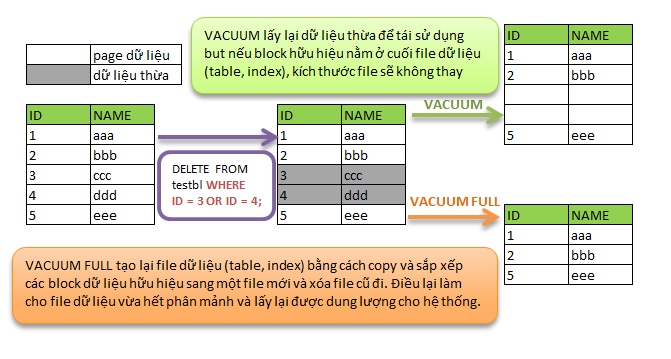
Như trong bài viết về VACUUM mình đã nói qua, PostgreSQL sử dụng cơ chế không xóa dữ liệu vật lý ngay mà chỉ đánh dấu đã xóa để thực hiện chức năng MVCC. Những dữ liệu bị đánh dấu đã xóa (dữ liệu bị phân mảnh) này, không được giải phóng ngay cả khi transaction đã COMMIT. Một trong những chức năng của VACUUM (autovacuum) là lấy lại những dữ liệu bị phân mảnh này để tái sử dụng. Như như hình vẽ minh họa bên dưới, dữ liệu dư thừa được lấy về để tái sử dụng khi VACUUM được thực thi đúng cách. But nếu block dữ liệu hữu hiệu nằm ở cuối file thì kích thước file không được giảm. Vấn đề trên làm cho dung lượng dư thừa không được trả về cho hệ thống. Ngoài ra nếu file dữ liệu lớn việc tìm seek dữ liệu trên đĩa cứng cũng ảnh hưởng tới performance.
VACUUM FULL vs VACUUM.
Ví dụ về hiệu quả của VACUUM FULL và REINDEX
Tạo dữ liệu test
postgres=# create table testtbl as select generate_series(1,100000) as id, random()::text as c1;
SELECT 100000
postgres=# create index test_idx on testtbl using btree (id);
CREATE INDEX
postgres=# analyze testtbl;
ANALYZE
postgres=# select pg_relation_size('testtbl');
pg_relation_size
------------------
5226496
(1 row)
postgres=# select pg_relation_size('test_idx');
pg_relation_size
------------------
2260992
(1 row)
Xóa một phần dữ liệu, để lại block dữ liệu ở cuối file và kiểm tra độ phân mảnh của table và index. Sau khi xóa tình dữ liệu. Tình trạng phân mảnh của table và index rõ dệt như bên dưới.
Ở đây mình sử dụng thêm contrib pgstattuple để kiểm tra độ phân mảnh của table và index.
postgres=# delete from testtbl where id < 99999;
DELETE 99998
postgres=# analyze testtbl;
ANALYZE
postgres=# select dead_tuple_percent,free_space from pgstattuple('testtbl');
dead_tuple_percent | free_space
--------------------+------------
88| 7904
(1 row)
postgres=# select avg_leaf_density,leaf_pages from pgstatindex('test_idx');
avg_leaf_density | leaf_pages
------------------+------------
89.83 | 274
(1 row)
VACUUM và kiểm tra dung lượng file và độ phân mảnh. Như kết quả bên dưới, tình trạng phân mảnh đã được phục hồi (đã lấy lại dữ liệu dư thừa) but dung lượng file không thay đổi.
Tiếp tục INSERT dữ liệu. Dữ liệu khi INSERT sử dụng được vùng block thừa vừa được thu hồi nên dung lượng file table không thay đổi, but do cấu tạo của INDEX mặc dù dữ liệu thừa đã được thu hồi (do chưa tối ưu được cách sử dụng?) nên file index vẫn tăng lên một chút.
Là chức năng tạo lại file index. Thực tế, chức năng này thường được sử dụng trong những trường hợp bên dưới.
Khắc phục tình trạng file index trở nên quá lớn trong vận hành. Như giải thích bên trên.
Khi index bị hỏng (thường không xảy ra, but như trường hợp bug của PostgreSQL).
Khi thay đổi định nghĩa về INDEX (ví dụ fillfactor) bằng câu lệnh ALTER INDEX.
REINDEX có thể thực hiện bằng lệnh SQL REINDEX hoặc câu lệnh binary reindexdb. Tùy vào cú pháp mà ta có thể thay đổi phạm vi thực hiện REINDEX.
Cú pháp thực hiện REINDEX (lệnh SQL)
postgres=# \h reindex
Command: REINDEX
Description: rebuild indexes
Syntax:
REINDEX [ ( VERBOSE ) ] { INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } name
Cú pháp reindexdb
$ reindexdb --help
reindexdb reindexes a PostgreSQL database.
Usage:
reindexdb [OPTION]... [DBNAME]
Options:
-a, --all reindex all databases
-d, --dbname=DBNAME database to reindex
-e, --echo show the commands being sent to the server
-i, --index=INDEX recreate specific index(es) only
-q, --quiet don't write any messages
-s, --system reindex system catalogs
-S, --schema=SCHEMA reindex specific schema(s) only
-t, --table=TABLE reindex specific table(s) only
-v, --verbose write a lot of output
-V, --version output version information, then exit
-?, --help show this help, then exit
... còn nữa
VACUUM FULL
Là một chức năng của VACUUM. Ngoài chức năng VACUUM thông thường, VACUUM FULL thực hiện tạo lại file table và những index liên quan tới table tương ứng đó. VACUUM FULL có thể thực hiện bằng lệnh SQL hoặc câu lệnh binary vacuumdb -f. Tùy vào cú pháp mà ta có thể thay đổi phạm vi thực hiện VACUUM FULL.
$ vacuumdb --help
vacuumdb cleans and analyzes a PostgreSQL database.
Usage:
vacuumdb [OPTION]... [DBNAME]
Options:
-a, --all vacuum all databases
-d, --dbname=DBNAME database to vacuum
-e, --echo show the commands being sent to the server
-f, --full do full vacuuming
-F, --freeze freeze row transaction information
-j, --jobs=NUM use this many concurrent connections to vacuum
-q, --quiet don't write any messages
-t, --table='TABLE[(COLUMNS)]' vacuum specific table(s) only
-v, --verbose write a lot of output
-V, --version output version information, then exit
-z, --analyze update optimizer statistics
-Z, --analyze-only only update optimizer statistics; no vacuum
--analyze-in-stages only update optimizer statistics, in multiple
stages for faster results; no vacuum
... còn nữa
Chú ý khi sử dụng REINDEX và VACUUM FULL
REINDEX và VACUUM FULL có những chú ý như bên dưới. Bạn nên tham khảo kỹ trước khi sử dụng để hệ thống/service của bạn chịu ảnh hưởng ít nhất.
Thông thường, trường hợp vận hành lâu ngày table files và index files trở nên lớn khác thường so với lượng record hiện tại ta mới sử dụng VACUUM FULL.
Cả VACUUM và REINDEX đều thực hiện ACCESS EXCLUSIVE lock với table tương ứng. Điều này làm cho các transaction khác không thể access (kể cả SELECT) khi đang thực hiện.
REINDEX và VACUUM FULL thực hiện tạo Objects(index, table) file tạm trước (sau đó xóa Objects file cũ đi), nên khi chạy cần dung lượng = 2 lần dung lượng objects (index, table) hiện tại.
REINDEX, VACUUM FULL tạo lại objects (index, table) file nên phát sinh Disk I/O lớn.
VACUUM FULL thực hiện cả việc tạo lại INDEX tương ứng của đối tượng table được chỉ định (từ phiên bản 9.0).
Chào các bạn. Bài viết này mình xin giới thiệu thêm về một chức năng cơ bản mà rất cần thiết khi thiết kế sử dụng một cơ sở dữ liệu PostgreSQL cho người sử dụng. Như tiêu đề đã nêu, đó là quản lý log. Log là một phần không thể thiếu trong việc giải quyết các vấn đề liên quan tới database như phát hiện lock wait, deadlock, tình trạng checkpoint, autovacuum, phát hiện slow query... Thiết kế sao cho log chứa những thông tin hữu ích để giải quyết những vấn đề xảy ra trong lúc hoạt động, và làm sao để việc xuất log không ảnh hưởng nhiều tới hệ thống là một phần không thể thiếu đối với một quản trị viên cơ sở dữ liệu.
Chức năng log của PostgreSQL
Log là chức năng có sẵn của PostgreSQL, ta có thể sử dụng mà không cần cài đặt thêm module nào cả. Chức năng log của PostgreSQL lưu trữ các thao tác, lỗi khi sử dụng, vận hành, ... dưới dạng text, cho phép người dùng có thể quan sát trực tiếp. PostgreSQL có thể thiết kế để xuất log tới syslog(linux) hay event log(windows), mặc định PostgreSQL xuất log bên dưới pg_log bên dưới thư mục cơ sở dữ liệu (nếu tham số logging_collector thiết lập là on). Để quản lý đơn giản hơn thường dữ liệu log được thiết lập để xuất bên dưới thư mục cơ sở dữ liệu. Bài viết này mình cũng đưa ra những ví dụ log từ pg_log bên dưới thư mục cơ sở dữ liệu.
Chú ý khi thiết kế log
Trạng thái xuất log mặc định
Giá trị khởi tạo của tham số logging_collector là off, tức là log messages không được lưu trữ. Nhưng nếu bạn tạo database cluster theo cách bên dưới đây thì giá trị mặc định đối với tham số logging_collector cho database cluster đó là on.
Database được tạo ra lúc cài đặt PostgreSQL bằng (EDB) Installer trên môi trường Windows.
Database được tạo ra bởi initdb được cài đặt từ rpm từ community.
Chú ý khác với initdb của rpm, database cluster được tạo ra bằng cách chạy trực tiếp lệnh initdb của EDB installer (ít nhất tại thời điểm hiện tại) lại có mặc định logging_collector = off.
Một số chú ý về log của PostgreSQL khi lưu trữ bên dưới thư mục dữ liệu
Mặc định log của PostgreSQL tăng không có giới hạn Mặc định các tham số log_filename, log_truncate_on_rotation làm cho log không có cơ chế loại bỏ được log cũ nên dung lượng log sẽ tăng không ngừng theo thời gian. Ta phải thiết kế để tránh tình trạng trên và sao cho phù hợp với yêu cầu hệ thống.
Không thể giới hạn được dung lượng xuất log của PostgreSQL Như giải thích về tham số log_rotate_size ở bên dưới. Chúng ta không thể giới hạn được dung lượng xuất log của PostgreSQL. Bởi vậy nên cần tính toán thiết kế sao cho lượng log không xuất ra quá nhiều so với mong đợi.
Các tham số liên quan tới log của PostgreSQL
PostgreSQL có rất nhiều paramters liên quan tới log, nội dung giải thích bên dưới mình chỉ tập chung vào các tham số thường được sử dụng trong vận hành và lúc tuning (tinh chỉnh). Cụ thể các tham số đó vui lòng tham khảo ở Document của PostgreSQL.
Các tham số liên quan tới PostgreSQL được chia ra 3 nhóm chính. Mình sẽ đi vào giải thích các tham số trong từng nhóm.
Trong các tham số liên quan tới log, duy có tham số logging_collector khi thay đổi cần restart server(pg_ctl restart) để có hiệu lực. Các paramter khác có thể reload server(pg_ctl reload), hoặc một vài paramter có thể thiết lập trong từng session(bằng cách sử dụng câu lệnh SET).
Nơi xuất log
tên paramter
chức năng
chú thích
log_destination
Tham số chỉ định nơi xuất log.
PostgreSQL có 3 phương pháp chỉ định nơi xuất log, stderr: bên dưới database cluster (pg_log or log) dưới dạng text, csvlog: như stderr nhưng xuất theo định dạng csv, syslog: xuất log ra log hệ thống(linux OS), eventlog: xuất log ra event log trên môi trường Windows. Mặc định giá trị của tham số này là 'stderr'.
Ta có thể chỉ định nhiều nơi xuất log qua dấu phân cách ",". Ví dụ log_destination = 'stderr, eventlog' # xuất log dạng text vào $PGDATA/log và eventlog trên Windows.
Thực tế để quản lý log dễ dàng hơn tham số này thường được để mặc định.
logging_collector
Tham số chỉ định cho phép lưu trữ log vào file hay không.
Mặc định cho là off khi tạo database cluster bằng lệnh initdb. Khi thay đổi giá trị, cần khởi động lại server để có hiệu lực.
Tham số này chỉ có hiệu quả khi log_destination là csvlog hay stderr.
log_directory
Tham số chỉ định nơi lưu log khi log_destination là stderr hoặc csvlog
Từ phiên bản PostgreSQL 10 mặc định cho tham số này chuyển từ pg_log sang log. Các thư mục này nằm bên dưới thư mục cơ sở dữ liệu.
log_filename
Tham số chỉ định tên của file log
Giá trị chỉ định của tham số này giống như chuẩn Open Group's ftrtime. Bạn có thể chỉ định tên file log theo ngày(postgresql-%d.log: thiết lập này sẽ lưu số lượng log file bằng số ngày của tháng là 31), thứ trong tuần(postgresql-%a.log: thiết lập này sẽ lưu trữ số lượng log file bằng số lượng ngày trong tuần là 7),.. Mặc định giá trị cho tham số này là 'postgresql-%Y-%m-%d_%H%M%S.log' tức là tên log file sẽ chứa thời gian tới đơn vị giây. Đồng nghĩa với việc số lượng log file không kiểm soát được, ta nên chỉnh lại tham số này trước khi đưa vào vận hành.
Ví dụ: với thiết lập log_filename = 'postgresql-%a.log'. Trong vận hành ta sẽ có 7 log files(1 log file cho mỗi ngày trong tuần) như bên dưới.
$ ll $PGDATA/log/
total 16
-rw-------. 1 postgres postgres 0 May 4 00:00 postgresql-Fri.log
-rw-------. 1 postgres postgres 0 May 7 00:00 postgresql-Mon.log
-rw-------. 1 postgres postgres 1039 May 5 16:07 postgresql-Sat.log
-rw-------. 1 postgres postgres 0 May 6 00:00 postgresql-Sun.log
-rw-------. 1 postgres postgres 941 May 3 18:39 postgresql-Thu.log
-rw-------. 1 postgres postgres 74 May 11 23:55 postgresql-Tue.log
-rw-------. 1 postgres postgres 718 May 16 06:31 postgresql-Wed.log
log_file_mode
Tham số chỉ định quyền tham chiếu tới log file
Mặc định là 0600, nghĩa là chỉ có OS user sở hữu server (user dùng để khởi động PostgreSQL) là có thể tham chiếu tới log file.
log_rotation_age
Tham số chỉ định rotate log file(ghi sang log file khác khi tới ngưỡng chỉ định) theo thời gian
Mặc định là một ngày, tức là cứ sau 1 ngày log file mới sẽ được tạo ra theo định dạng chỉ định trong tham số log_filename.
log_rotation_size
Tham số chỉ định rotate log file(ghi sang log file khác khi tới ngưỡng chỉ định) theo kích thước
Mặc định là 10MB. Tức là cứ 10MB, sẽ có log file mới được tạo ra theo định dạng trong tham số log_filename. Lưu ý rằng log file mới tạo ra theo định dạng của log_filename, nên chỉ khi tên log file mới được tạo ra quá trình rotate mới xảy ra. Điều này dẫn đến ta không thể kiểm soát được dung lượng log xuất ra
log_truncate_on_rotation
Tham số chỉ định có truncate log cũ khi rotation hay không
Mặc định tham số này là off. Tức là không truncate(xóa) log cũ khi rotation thực thi. Nên dung lượng file log sẽ lớn dần theo thời gian. Nếu không có cơ chế backup log cụ thể nào nên để tham số này là on.
Chú ý rằng thời điểm thực hiện rotation dựa vào log_filename(ví dụ khi log_rotation_age=1d, log_filename='postgresql-%d.log' thì rotation sẽ diễn ra vào lúc 0 giờ hằng ngày). Tại thời điểm 0 giờ này nếu PostgreSQL đang dừng hoạt động thì xử lý truncate sẽ không diễn ra khi khởi động PostgreSQL, khi đó PostgreSQL chỉ chèn thêm log messages vào log file hiện tại.
Thời điểm xuất log
tên paramter
chức năng
chú thích
client_min_mesages
Tham số chỉ định mức độ mà log messages sẽ trả về cho phía client(khi chạy các câu lệnh SQL)
Mặc định cho tham số này là NOTICE. Tức là chỉ những messages có mức độ từ NOTICE trở lên(NOTICE, WARNING, ERROR, FATAL, PANIC) mới trả về cho client.
postgres=# set client_min_messages to log;
SET
postgres=# set log_min_duration_statement to 0;
LOG: duration: 0.103 ms statement: set log_min_duration_statement to 0;
SET
postgres=# select pg_sleep(1);
LOG: duration: 1003.193 ms statement: select pg_sleep(1);
pg_sleep
----------
(1 row)
log_min_messages
Tham số chỉ định mức độ mà log messages sẽ xuất phía server
Mặc định cho tham số này là WARNING. Tức là chỉ những messages có mức độ từ WARNING trở lên(WARNING, ERROR, LOG, FATAL, PANIC) mới được xuất. Tham số này hữu ích khi điều tra vấn đề gì đó xảy ra trên server của bạn.
$ psql
psql (11devel)
Type "help" for help.
postgres=# set log_min_messages to debug5;
SET
postgres=# select count(*) from pg_class;
count
-------
343
(1 row)
postgres=# \q
$ tail -2 $PGDATA/log/postgresql-Wed.log | grep DEBUG
2018-05-16 07:42:50.299 JST [22540] DEBUG: shmem_exit(-1): 0 on_shmem_exit callbacks to make
2018-05-16 07:42:50.299 JST [22540] DEBUG: proc_exit(-1): 0 callbacks to make
$
log_min_error_statement
Tham số chỉ định khi nào sẽ xuất câu lệnh SQL liên quan tới log messages hiện tại
Mặc định cho tham số này là ERROR. Tức là đối với các messages có mức độ từ ERROR trở lên (ERROR, LOG, FATAL, PANIC) khi xuất ra sẽ kèm với câu lệnh SQL tương ứng
postgres=# show log_min_error_statement;
log_min_error_statement
-------------------------
error
(1 row)
postgres=# select testerror;
ERROR: column "testerror" does not exist
LINE 1: select testerror;
^
postgres=# \q
$ tail -3 $PGDATA/log/postgresql-Wed.log | grep ERROR -A2
2018-05-16 07:45:51.324 JST [22591] ERROR: column "testerror" does not exist at character 8
2018-05-16 07:45:51.324 JST [22591] STATEMENT: select testerror;
$
log_min_duration_statement
Tham số chỉ định sẽ xuất log cho những SQL có thời gian thực thi lớn hơn giá trị chỉ định(đơn vị là mili giây)
Mặc định cho tham số này là -1 tức là sẽ không xuất các câu lệnh SQL đã chạy. Tham số này rất hữu ích cho việc xác định slow query trong PostgreSQL. Ví dụ: nếu thiết lập giá trị là '10s', những SQL nào chạy quá 10s sẽ được xuất ra log
postgres=# set client_min_messages to log;
SET
postgres=# set log_min_duration_statement to 100;
LOG: duration: 0.103 ms statement: set log_min_duration_statement to 100;
SET
postgres=# select pg_sleep(1);
LOG: duration: 1003.193 msstatement: select pg_sleep(1);
pg_sleep
----------
(1 row)
Nội dung log
tên paramter
chức năng
chú thích
log_connections
Tham số chỉ định log thông tin khi kết nối.
Mặc định tham số này là off, tức là ko log khi kết nối. Thực tế khi tham số này on thì mỗi lần kết nối dung lượng log cũng không xuất ra nhiều (2 dòng), ta nên để on để phân tích log dễ dàng hơn. Tham số này chỉ chỉ định được trước khi bắt đầu session.
Tham số chỉ định lượng log chi tiết xuất ra cho mỗi messages
Giá trị có thể thiết lập là, TERSE, DEFAULT, và VERBOSE. Ở thiết lập TERSE, những thông tin DETAIL, HINT, QUERY và CONTEXT không được xuất. VERBOSE ngoài việc xuất những thông tin này ra, vị trí dòng code, tên hàm, tên file source code cũng được hiện thị. Những hệ thống có workload nhỏ có thể thiết lập lên VERBOSE để phân tích log dễ dàng hơn
log_duration
Tham số cho phép xuất thời gian đã thực thi của mỗi câu lệnh SQL
Mặc định tham số này là off và chỉ có super user mới thay đổi được
postgres=# set log_duration to on;
SET
postgres=# set client_min_messages to log;
LOG: duration: 0.075 ms
SET
postgres=# select pg_sleep(1);
LOG: duration: 1002.341 ms
pg_sleep
----------
(1 row)
postgres=#
log_line_prefix
Tham số chỉ định tiền tố cho mỗi log messages
Tham số này có thể chỉ định theo ký tự % cho các thông tin khác nhau, cụ thể bạn có thể xem tại đây. Từ phiên bản 10 mặc định cho tham số này là '%m [%p] ', tức là thông tin về thời gian bao gồm cả mili giây(%m) và ID của tiến trình thực hiện log(%p). Thông thường để phân tích log khi có sự cố, ta thường thêm các thông tin như %d: truy cập cơ sở dữ liệu nào, %h: truy cập từ IP address nào, %u: truy cập bằng user nào, %x: trong transaction ID nào.
Tham số cho phép log các lệnh SQL thực thi theo từng chủng loại chỉ định
Giá trị cho phép là off(mặc định), ddl: các câu lệnh SQL liên quan tới định nghĩa (CREATE, ALTER, DROP), mod: các câu lệnh SQL liên quan tới thay đổi dữ liệu(INSERT, UPDATE, DELETE, TRUNCATE,...), all: tất cả các câu lệnh SQL. Lưu ý thiết lập all cho tham số này có ý nghĩa tương tự như thiết lập tham số log_min_duration_statement = 0, nhưng log_min_duration_statement xuất các câu lệnh SQL khi đã thực thi xong còn log_statement log khi câu lệnh vừa được chạy(có thể chưa hoặc kết thúc). Tùy vào yêu cầu về mornitoring hệ thống, ta có thể kết hợp tham số này với log_duration hoặc chỉ sử dụng log_min_duration_statement để theo dõi các câu lệnh SQL thực thi
postgres=# set log_statement to 'ddl';
SET
postgres=# set client_min_messages to log;
SET
postgres=# create table testtbl(id integer);
LOG: statement: create table testtbl(id integer);
CREATE TABLE
postgres=# insert into testtbl values(1);
INSERT 0 1
postgres=# drop table testtbl ;
LOG: statement: drop table testtbl ;
DROP TABLE
postgres=#
log_temp_files
Cho phép log khi có file tạm xuất ra tùy thuộc vào dung lượng file chỉ định
Đối với xử lý như hashjoin hay sort, PostgreSQL sử dụng bộ nhớ chỉ định trong tham số work_mem(cho mỗi process) để chứa dữ liệu tạm thời. Khi dữ liệu tạm thời vượt quá work_mem, PostgreSQL sẽ thực hiện sort/hashjoin trên đĩa cứng. Khi dung lượng file tạm sử dụng cho sort/hashjoin trên đĩa cứng lớn hơn log_temp_files, logger process sẽ xuất thông tin đó ra log file.
postgres=# set log_temp_files to 0;
SET
postgres=# set work_mem to 64;
SET
postgres=# show work_mem ;
work_mem
----------
64kB
(1 row)
postgres=# explain analyze select * from pg_class order by relname desc;
QUERY PLAN
----------------------------------------------------------------------------------------------------
-----------
Sort (cost=75.31..76.17 rows=342 width=262) (actual time=0.636..0.720 rows=343 loops=1)
Sort Key: relname DESC
Sort Method: external merge Disk: 64kB
-> Seq Scan on pg_class (cost=0.00..15.42 rows=342 width=262) (actual time=0.010..0.067 rows=34
3 loops=1)
Planning Time: 0.862 ms
Execution Time: 1.025 ms
(6 rows)
postgres=# \! tail -2 $PGDATA/log/postgresql-Wed.log
2018-05-16 08:10:36.530 JST [23134] LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp23134.0", size 65536
2018-05-16 08:10:36.530 JST [23134] STATEMENT: explain analyze select * from pg_class order by relname desc;
postgres=#
log_checkpoints
Cho phép log thông tin CHECKPOINT khi chức năng này thực thi
Mặc định cho tham số này là off. Tham số này cần thiết khi tinh chỉnh hệ thống liên quan tới bộ nhớ đệm và tần xuất lưu lượng mỗi CHECKPOINT. Bạn có thể tham khảm thêm ở bài viết checkpoint
log_lock_waits
Tham số chỉ định xuất log liên quan khi lock wait cho session đó vượt quá thời gian chỉ định trong deadlock_timeout
Mặc định cho tham số này là off. Nếu on PostgreSQL sẽ xuất log liên quan cho phiên đó khi quá thời gian deadlock_timeout(mặc định 1 giây) mà chưa thực thi được lock. Trong các hệ thống có work load (bạn có thể hiểu là tần xuất thực thi SQL) lớn, tham số này rất hữu ích cho việc tìm hiểu nguyên nhân slow query do lock wait hoặc phát hiện deadlock. Bạn có thể tham khảo thêm ở bài viết về lock
Cũng như các RDBMS khác. PostgreSQL cung cấp chức năng cho phép nhiều người dùng có thể truy cập và xử lý dữ liệu dữ liệu cùng một lúc mà không xảy ra xung đột. Tuỳ thuộc vào mức độ phân ly transaction (transaction isolation level) của PostgreSQL mà dữ liệu được nhìn thấy, xử lý như thế nào trong mỗi transaction. Để thực hiện các xử lý này mỗi khi xử lý một tài nguyên (ví dụ như bảng dữ liệu, dòng dữ liệu), phải có cơ chế lock tài nguyên này lại không cho tiến trình khác có thể can thiệp vào được. PostgreSQL cung cấp nhiều kiểu lock để xử lý dữ liệu. Ví dụ: khi bạn SELECT nội dung đối tượng SELECT (bảng dữ liệu) sẽ bị yêu cầu ACCESS SHARE lock, khi UPDATE, DELETE dữ liệu đối tượng UPDATE, DELETE (dòng dữ liệu) sẽ bị yêu cầu ROW EXCLUSIVE lock, sau khi lock thành công lock này sẽ tồn tại tới khi transaction trong phiên làm việc đó kết thúc.
Các kiểu lock trên bảng dữ liệu PostgreSQL
Các kiểu lock cho bảng dữ liệu PostgreSQL bạn có thể tham khảo chi tiết từ document của PostgreSQL tại đây.
Câu truy vấn sẽ ở trạng thái chờ khi có một lock xung đột xảy ra trên bảng dữ liệu muốn truy vấn. Như ví dụ bên dưới, khi bảng testtbl đang bị lock ACCESS SHARE bởi một session khác. Câu truy vấn xung đột với ACCESS SHARE (TRUNCATE) sẽ bị trạng thái chờ (lock wait) cho tới khi lock ACCESS SHARE được giải phóng.
postgres=# select * from pg_locks where relation = (select oid from pg_class where relname = 'testtbl');
-[ RECORD 1 ]------+-------------
locktype | relation
database | 12558
relation | 24576
page |
tuple |
virtualxid |
transactionid |
classid |
objid |
objsubid |
virtualtransaction | 3/829
pid | 5605
mode | RowShareLock
granted | t
fastpath | t
postgres=# truncate testtbl ;
trạng thái chờ (lock wait) nhìn từ process hệ thống.
trạng thái lock wait trên database rất hay xảy ra khi logic application chưa đúng. Để troubleshoot trường hợp này ta thường tham khảo 2 view pg_stat_activity và pg_locks. Cách sử dụng xin vui lòng xem ở cuối bài viết này.
Lock wait sẽ xảy ra khi có xung đột như các trường hợp "X" bên dưới (trích dẫn từ Documents của PostgreSQL).
Xung đột lock ở mức độ bảng
Loại Lock yêu cầu
Loại lock đang thực thi
ACCESS SHARE
ROW SHARE
ROW EXCLUSIVE
SHARE UPDATE EXCLUSIVE
SHARE
SHARE ROW EXCLUSIVE
EXCLUSIVE
ACCESS EXCLUSIVE
ACCESS SHARE
X
ROW SHARE
X
X
ROW EXCLUSIVE
X
X
X
X
SHARE UPDATE EXCLUSIVE
X
X
X
X
X
SHARE
X
X
X
X
X
SHARE ROW EXCLUSIVE
X
X
X
X
X
X
EXCLUSIVE
X
X
X
X
X
X
X
ACCESS EXCLUSIVE
X
X
X
X
X
X
X
X
Các trường hợp lock xảy xảy ra ở mức độ dòng
Locks xảy ra với dòng có các mức độ như FOR UPDATE, FOR NO KEY UPDATE, FOR SHARE, FOR KEY SHARE tương ứng với khi chạy các câu truy vấn SELECT ... FOR UPDATE, FOR NO KEY UPDATE, FOR SHARE, FOR KEY SHARE. Lưu ý là locks xảy ra với dòng không xác nhận qua pg_locks view mà phải xác nhận thông qua pgrowlocks. Các xung đột xảy ra ở mức độ dòng được tóm tắt như bên dưới (trích dẫn từ Documents của PostgreSQL).
Mặc định transaction level cuả PostgreSQL (read committed) cho phép transaction khác ghi dữ liệu khi dữ liệu đó đang được tham chiếu. Điều này có thể làm cho logic của application chạy không đúng, như trường hợp kiểm tra dữ liệu hiện tại sau đó thực hiện câu lệnh cập nhật dữ liệu (dữ liệu lúc cập nhật có thể đã bị thay đổi bởi transaction khác). Trong những trường hợp này ta có thể sử dụng câu lệnh SELECT ... FOR UPDATE để giải quyết, câu lệnh này block dữ liệu đang tham chiếu tại lệnh (SELECT) tới khi transaction hiện tại kết thúc.
Các trường hợp xung đột lock ở mức độ dòng
Requested Lock Mode
Current Lock Mode
FOR KEY SHARE
FOR SHARE
FOR NO KEY UPDATE
FOR UPDATE
FOR KEY SHARE
X
FOR SHARE
X
X
FOR NO KEY UPDATE
X
X
X
FOR UPDATE
X
X
X
X
Cách xác định tình trạng locks
Thông thường locks xác định thông qua view pg_locks. Trường granted cho biết locks đã thực hiện được chưa. nếu locks trong tình trạng waiting, giá trị của granted sẽ là false(t), trường hợp ngược lại sẽ là true.
như kết quả ví dụ bên dưới. Đối với bảng dữ liệu testtbl, process với PID: 24289 đã lock thành công(granted = t) với mode AccessExclusiveLock. Ở một phiên làm việc (kết nối) khác với PID: 24283 câu truy vấn tới sau cũng muốn lock với mode AccessExclusiveLock và đã bị ở trạng thái chờ(granted = f).
postgres=# select locktype,relation,pid,mode,granted,fastpath from pg_locks where relation = (select oid from pg_class where relname = 'testtbl');
locktype | relation | pid | mode | granted | fastpath
----------+----------+-------+---------------------+---------+----------
relation | 24576 | 24283 | AccessExclusiveLock | f | f
relation | 24576 | 24289 | AccessExclusiveLock | t | f
(2 rows)
Muốn xác định 2 câu truy vấn nào đang diễn ra, ta xem kết quả của view pg_stat_activity. Như kết quả bên dưới ta xác định được phiên làm việc nào, câu truy vấn nào đang bị ở trạng thái chờ, và phiên làm việc nào đang bị chờ.
postgres=# select datname,pid,wait_event_type,wait_event,state,query from pg_stat_activity where pid = 24283 or pid = 24289;
datname | pid | wait_event_type | wait_event | state | query
----------+-------+-----------------+------------+---------------------+----------------
postgres | 24289 | Client | ClientRead | idle in transaction | lock testtbl ;
postgres | 24283 | Lock | relation | active | lock testtbl ;
(2 rows)
Locks wait là một trường hợp điển hình của thiết kế client chưa được tốt, nên khi phát hiện nên xử lý logic phía client hơn là chỉnh tham số lock_timeout. Lưu ý nếu có thiết lập tham số lock_timeout cũng không nên chỉnh trong postgresql.conf, vì nó sẽ ảnh hưởng tới toàn bộ database cluster. Có thể chỉnh tham số này thông qua từng phiên làm việc (câu lệnh SET), hoặc USER, DATABASE (lệnh ALTER ... SET ... ).
Ngoài ra để kiểm tra tình trạng lock wait, ta có thể chỉnh tham số log_lock_waits = on, khi thời gian wait vượt quá giá trị deadlock_timeout PostgreSQL sẽ xuất log messages như bên dưới (đã waited 1001.236 ms nhưng chưa thành công).
LOG: process 24289 still waiting for AccessExclusiveLock on relation 24576 of database 12558 after 1001.236 ms
DETAIL: Process holding the lock: 24283. Wait queue: 24289.
STATEMENT: lock testtbl ;
Khi lock thành công PostgreSQL sẽ xuất log messages như bên dưới (thành công sau 11409.427 ms waited).
LOG: process 24289 acquired AccessExclusiveLock on relation 24576 of database 12558 after 11409.427 ms
STATEMENT: lock testtbl ;