Chào các bạn. Nhân tiện có bạn hỏi về REINDEX nên mình viết bài này để giải thích thêm về REINDEX và VACUUM FULL, khi nào phải thực hiện các thao tác này và cần chú ý những gì khi sử dụng chức năng này. Trong bài viết về VACUUM, mình có giải thích về chức năng và các xử lý mà VACUUM thực hiện. But chưa nói về 2 chức năng liên quan này. Trước khi bắt đầu giải thích về VACUUM FULL và REINDEX, mình xin trả lời trước một số nghi vấn mà lúc tiếp xúc với PostgreSQL các bạn hay gặp phải.
VACUUM có lấy lại dữ liệu phân mảnh cho INDEX không?
Câu trả lời là có. VACUUM lấy lại dữ liệu phân mảnh cho table và những index tương ứng của table đó. But không giống với table, index không có Visibility Map(VM) nên VACUUM thực hiện scan toàn bộ file index tốn nhiều disk I/O để tìm kiếm và thực hiện lấy lại dữ liệu dư thừa. Đây cũng là một điểm bất lợi về performance của VACUUM.
Tại sao cần REINDEX hay VACUUM FULL?
Lý do chính trong vận hành khi thực hiện 2 chức năng này là để khắc phục tình trạng file dữ liệu (table hay index) bị tăng quá lớn.
Hai chức năng này khi chạy sẽ ảnh hưởng nhiều tới hệ thống. Bạn nên tham khảo kỹ chú ý ở cuối bài viết này rồi thực hiện cho đúng.
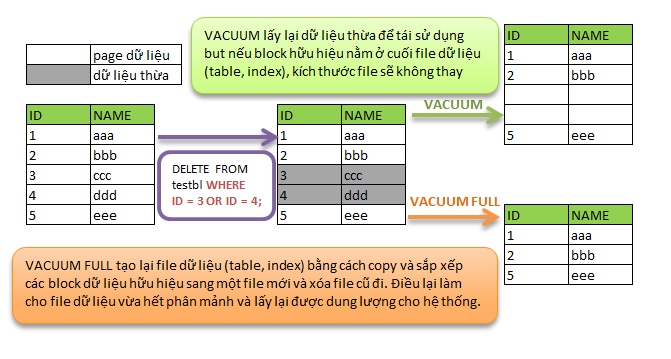
Như trong bài viết về VACUUM mình đã nói qua, PostgreSQL sử dụng cơ chế không xóa dữ liệu vật lý ngay mà chỉ đánh dấu đã xóa để thực hiện chức năng MVCC. Những dữ liệu bị đánh dấu đã xóa (dữ liệu bị phân mảnh) này, không được giải phóng ngay cả khi transaction đã COMMIT. Một trong những chức năng của VACUUM (autovacuum) là lấy lại những dữ liệu bị phân mảnh này để tái sử dụng. Như như hình vẽ minh họa bên dưới, dữ liệu dư thừa được lấy về để tái sử dụng khi VACUUM được thực thi đúng cách. But nếu block dữ liệu hữu hiệu nằm ở cuối file thì kích thước file không được giảm. Vấn đề trên làm cho dung lượng dư thừa không được trả về cho hệ thống. Ngoài ra nếu file dữ liệu lớn việc tìm seek dữ liệu trên đĩa cứng cũng ảnh hưởng tới performance.
VACUUM FULL vs VACUUM.
Ví dụ về hiệu quả của VACUUM FULL và REINDEX
Tạo dữ liệu test
postgres=# create table testtbl as select generate_series(1,100000) as id, random()::text as c1;
SELECT 100000
postgres=# create index test_idx on testtbl using btree (id);
CREATE INDEX
postgres=# analyze testtbl;
ANALYZE
postgres=# select pg_relation_size('testtbl');
pg_relation_size
------------------
5226496
(1 row)
postgres=# select pg_relation_size('test_idx');
pg_relation_size
------------------
2260992
(1 row)
Xóa một phần dữ liệu, để lại block dữ liệu ở cuối file và kiểm tra độ phân mảnh của table và index. Sau khi xóa tình dữ liệu. Tình trạng phân mảnh của table và index rõ dệt như bên dưới.
Ở đây mình sử dụng thêm contrib pgstattuple để kiểm tra độ phân mảnh của table và index.
postgres=# delete from testtbl where id < 99999;
DELETE 99998
postgres=# analyze testtbl;
ANALYZE
postgres=# select dead_tuple_percent,free_space from pgstattuple('testtbl');
dead_tuple_percent | free_space
--------------------+------------
88| 7904
(1 row)
postgres=# select avg_leaf_density,leaf_pages from pgstatindex('test_idx');
avg_leaf_density | leaf_pages
------------------+------------
89.83 | 274
(1 row)
VACUUM và kiểm tra dung lượng file và độ phân mảnh. Như kết quả bên dưới, tình trạng phân mảnh đã được phục hồi (đã lấy lại dữ liệu dư thừa) but dung lượng file không thay đổi.
Tiếp tục INSERT dữ liệu. Dữ liệu khi INSERT sử dụng được vùng block thừa vừa được thu hồi nên dung lượng file table không thay đổi, but do cấu tạo của INDEX mặc dù dữ liệu thừa đã được thu hồi (do chưa tối ưu được cách sử dụng?) nên file index vẫn tăng lên một chút.
Là chức năng tạo lại file index. Thực tế, chức năng này thường được sử dụng trong những trường hợp bên dưới.
Khắc phục tình trạng file index trở nên quá lớn trong vận hành. Như giải thích bên trên.
Khi index bị hỏng (thường không xảy ra, but như trường hợp bug của PostgreSQL).
Khi thay đổi định nghĩa về INDEX (ví dụ fillfactor) bằng câu lệnh ALTER INDEX.
REINDEX có thể thực hiện bằng lệnh SQL REINDEX hoặc câu lệnh binary reindexdb. Tùy vào cú pháp mà ta có thể thay đổi phạm vi thực hiện REINDEX.
Cú pháp thực hiện REINDEX (lệnh SQL)
postgres=# \h reindex
Command: REINDEX
Description: rebuild indexes
Syntax:
REINDEX [ ( VERBOSE ) ] { INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } name
Cú pháp reindexdb
$ reindexdb --help
reindexdb reindexes a PostgreSQL database.
Usage:
reindexdb [OPTION]... [DBNAME]
Options:
-a, --all reindex all databases
-d, --dbname=DBNAME database to reindex
-e, --echo show the commands being sent to the server
-i, --index=INDEX recreate specific index(es) only
-q, --quiet don't write any messages
-s, --system reindex system catalogs
-S, --schema=SCHEMA reindex specific schema(s) only
-t, --table=TABLE reindex specific table(s) only
-v, --verbose write a lot of output
-V, --version output version information, then exit
-?, --help show this help, then exit
... còn nữa
VACUUM FULL
Là một chức năng của VACUUM. Ngoài chức năng VACUUM thông thường, VACUUM FULL thực hiện tạo lại file table và những index liên quan tới table tương ứng đó. VACUUM FULL có thể thực hiện bằng lệnh SQL hoặc câu lệnh binary vacuumdb -f. Tùy vào cú pháp mà ta có thể thay đổi phạm vi thực hiện VACUUM FULL.
$ vacuumdb --help
vacuumdb cleans and analyzes a PostgreSQL database.
Usage:
vacuumdb [OPTION]... [DBNAME]
Options:
-a, --all vacuum all databases
-d, --dbname=DBNAME database to vacuum
-e, --echo show the commands being sent to the server
-f, --full do full vacuuming
-F, --freeze freeze row transaction information
-j, --jobs=NUM use this many concurrent connections to vacuum
-q, --quiet don't write any messages
-t, --table='TABLE[(COLUMNS)]' vacuum specific table(s) only
-v, --verbose write a lot of output
-V, --version output version information, then exit
-z, --analyze update optimizer statistics
-Z, --analyze-only only update optimizer statistics; no vacuum
--analyze-in-stages only update optimizer statistics, in multiple
stages for faster results; no vacuum
... còn nữa
Chú ý khi sử dụng REINDEX và VACUUM FULL
REINDEX và VACUUM FULL có những chú ý như bên dưới. Bạn nên tham khảo kỹ trước khi sử dụng để hệ thống/service của bạn chịu ảnh hưởng ít nhất.
Thông thường, trường hợp vận hành lâu ngày table files và index files trở nên lớn khác thường so với lượng record hiện tại ta mới sử dụng VACUUM FULL.
Cả VACUUM và REINDEX đều thực hiện ACCESS EXCLUSIVE lock với table tương ứng. Điều này làm cho các transaction khác không thể access (kể cả SELECT) khi đang thực hiện.
REINDEX và VACUUM FULL thực hiện tạo Objects(index, table) file tạm trước (sau đó xóa Objects file cũ đi), nên khi chạy cần dung lượng = 2 lần dung lượng objects (index, table) hiện tại.
REINDEX, VACUUM FULL tạo lại objects (index, table) file nên phát sinh Disk I/O lớn.
VACUUM FULL thực hiện cả việc tạo lại INDEX tương ứng của đối tượng table được chỉ định (từ phiên bản 9.0).